







港聞更多
林素蔚關注有否新增垃圾黑點 葛珮帆促更好規劃收集廚餘路線
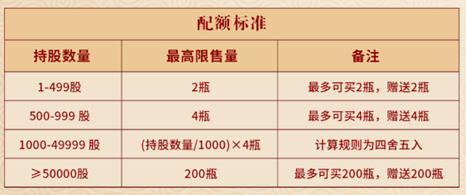
垃圾收費「先行先試」計劃本月起實施,環境及生態局局長謝展寰說,當局會細心留意「先行先試」期間遇到的問…



中國新聞更多

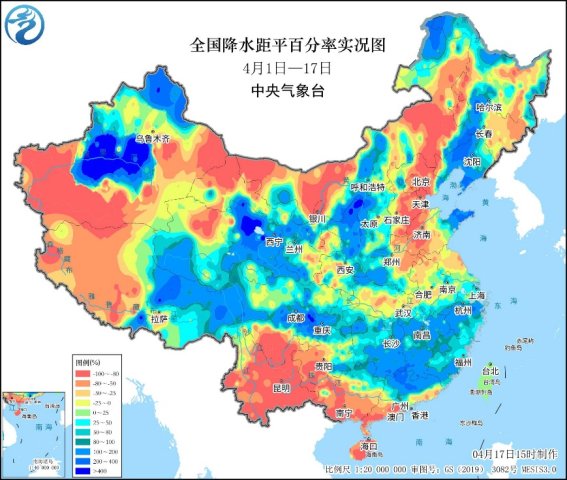
近日,春季過敏高發期到來
近日,春季過敏高發期到來。近一週以來,#氯雷他定#在京東買藥平台上的搜索量環比提升了121%;訂單量…


焦點娛聞

炎明熹重啟演唱會【影片】
去年因受颱風影響而要取消尾場的炎明熹Gigi首個個人演唱會,時隔近半年之後再次舉行,炎明熹連唱多首歌…




體育報導

代表海口出征!曹琦將駕駛AMG參加亞洲頂級GT賽事
4月19—21日,在海口市的支持下,車手曹琦將駕駛Mercedes-AMG GT3賽車參加亞洲地區頂…




今日財經

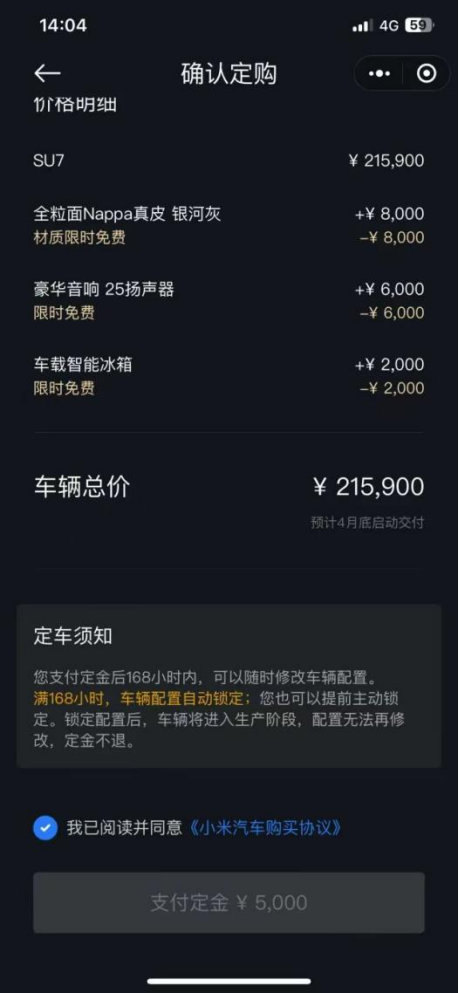
進入規模化時代!通用技術環球醫療腎病專科再收購5家醫療機構
4月13日,通用技術環球醫療旗下腎病專科業務平台——環球悅穀醫療科技(天津)有限公司(簡稱“環球悅穀…


熱門科技

高於國標10倍,超強防曬天石鵝鎧甲防曬風殼
大家好,我是夢想是個豬,今天為大家帶來的是天石鵝鎧甲防曬風殼的使用體驗。這幾年每到夏天,防曬衣就會非…



BEAUTY

路易威登寰遊時裝秀即將登陸上海
#周冬雨[超話]##LV明星路透# 路易威登寰遊時裝秀即將登陸上海,@周冬雨 獨家路透圖來啦!一身襯…




生活消閒

將軍澳好去處|4大將軍澳拍拖勝地推薦!必去溜冰場、海景Café【同場加映:康城全新人氣樓盤 PARK SEASONS最啱二人世界!】
【將軍澳好去處】想跟另一半享受甜蜜的周末?四大將軍澳拍拖好去處推薦!有溜冰場、海景Cafe、單車館、…



